
This is the first in a series of posts about fixing LabTech patching. This came up with the Wannacry ransomware that caused all partners to take a closer look at their patching setup.
Many of our machines are showing no patch inventory present, but are installing patches anyway. Even more interesting, these computers have run patch jobs. The scores aren’t updating and the last patch Inventory is Unknown:

Working with support, we found that clicking Resend to force an update to the inventory will solve the problem for that machine. However, I wanted to find a way to automate this.
NOTE: A previous version of this post incorrectly referenced the computerpatchcompliancestats table. While that information is available there, it requires finding all rows that are in one table and not another. Additionally, computerpatchcompliancestatsgets regenerated by the database agent once per day and won’t be up to date after a successful scan.
Information about when the last inventory was scanned is stored in the WindowsUpdate column of the computers table.
To find machines with this problem, look for rows without any value for the WindowsUpdate column. Note that this isn’t NULL but an empty string:
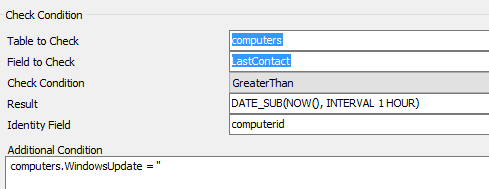
You might also find machines that instead of having an empty have the epoch listed. Checking the database tables for this issue, some will be: 1600-12-31 19:00:00 (I had to look this up as I hadn’t seen that as the epoch before). Ones that have this value are likely broken and will require more than this script to fix (see the next post).
Next, create an alert template against this monitor that runs a script to execute the resend patch information command.
This is a one-line script that updates the inventory:
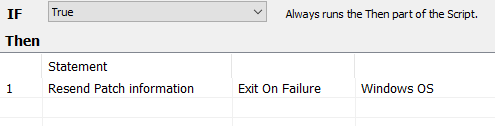
This has made short work of the ‘No Inventory’ problem. You can use a similar issue to address machines that haven’t had a patch scan in a certain interval of time because of the configured schedules.
